Publication
ICWSM 2024
sentibank


Machines have been trying to decode human emotions since 1962, and they were all doing it differently. Some use ordinal scores (-5 to +5). Others assign discrete labels (positive/negative). A few venture into vector representations across affective dimensions. This was the beautiful chaos of Software 1.0 — handcrafted rules encoding human intuition about emotional language. And after six months of digital archaeology, we realised nobody had ever brought them all together. Until now.
The Chaos of Sentiment Dictionaries
We discovered that sentiment dictionaries — carefully crafted lists of words with emotional scores — were scattered across the digital universe like fragments of an ancient manuscript. Some lived in dusty GitHub repositories as .py files. Others hid in paper appendices as .txt dumps. A few were trapped in websites as .xml schemas, while others floated in supplementary materials as .csv files or exotic .rdf formats.
Even better, 60% of these “validated” dictionaries contained duplicates with conflicting labels. For example, the word 'smash' appeared in one dictionary scored as both positive and negative. But the problems went deeper than internal inconsistencies. These dictionaries were also scattered across completely different ecosystems. It was like 15 different research teams had each invented their own emotional language, and nobody was talking to each other.
Building the Rosetta Stone of Sentiment
So we did what any reasonable researchers would do. We became digital archaeologists. We excavated 15 original sentiment dictionaries from across the internet, each with its own origin story:
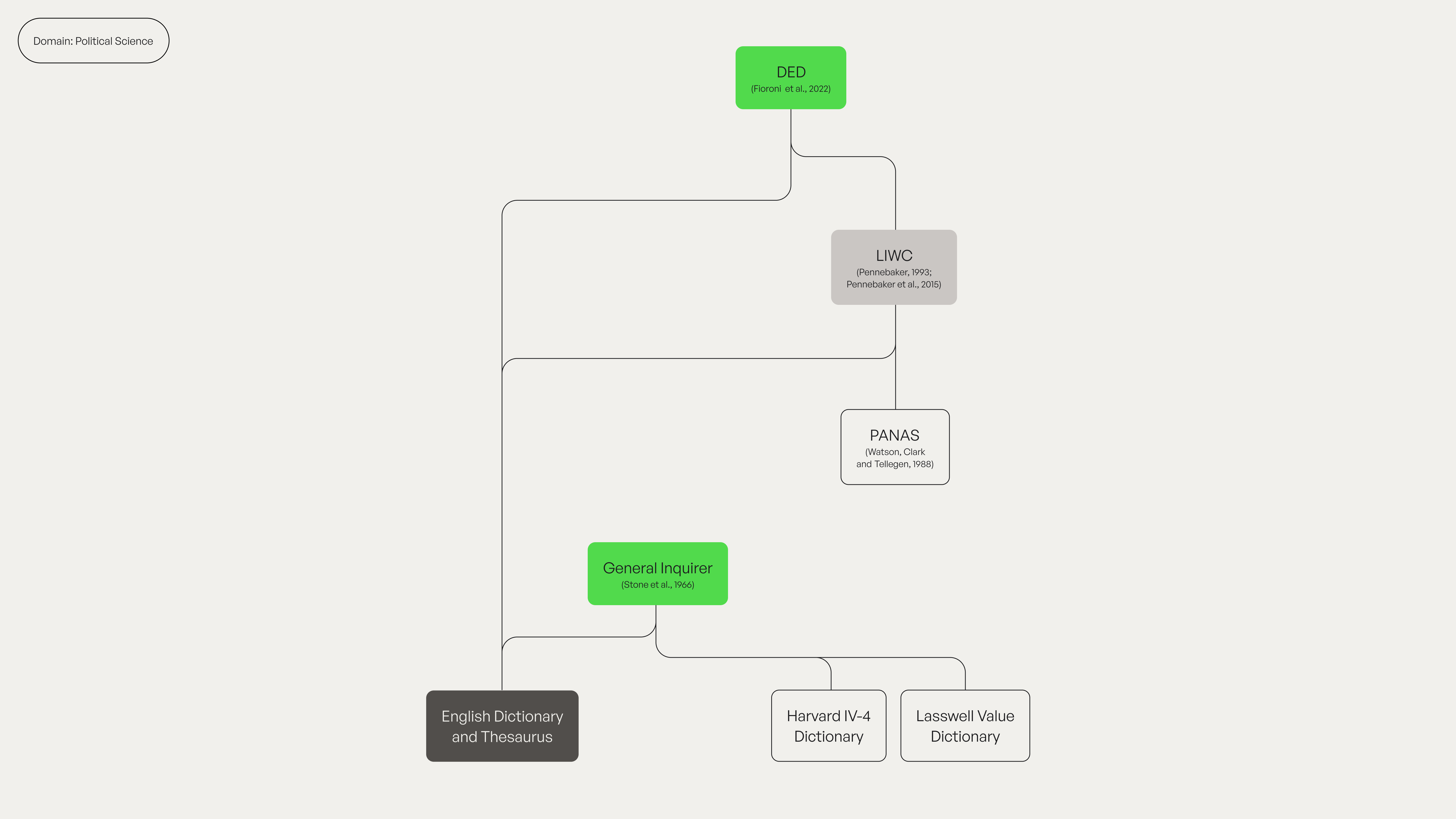
- General Inquirer (1962): The grandfather of them all, categorising words along psycholinguistic dimensions when computers still used punch cards.
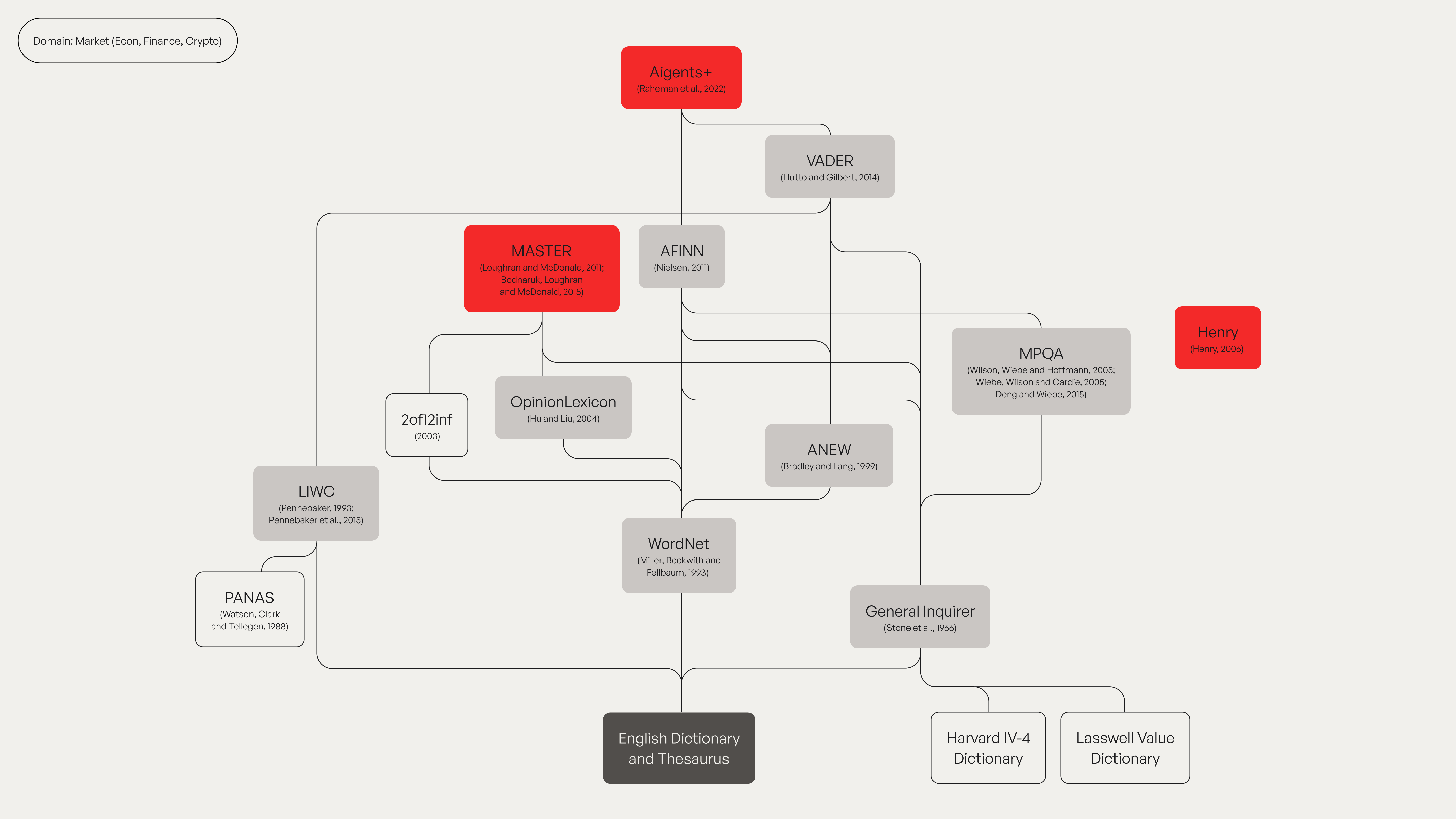
- VADER (2014): Optimised for social media, because “LOL” and “ugh” needed emotional scores too.
- MASTER (2011): Built for financial texts, where “liability” isn't always a liability.
- DED (2023): Capturing discrete emotions in political communication (anger, anxiety, sadness, and that rarest of political emotions — optimism).


What We Actually Built
After six months of digital archaeology and more data cleaning than any human should endure, we created sentibank:
- 15 original dictionaries: The grandfather of them all, categorising words along psycholinguistic dimensions when computers still used punch cards.
- 43 preprocessed versions: Cleaned, deduplicated, and standardised (including experiments like
NoVAD_v2013_boosted). - Spanning 7 genres and 6 domains: From social media to financial filings.
- One unified API : Because life's too short to parse 15 different file formats.
We turned digital archaeology into a living laboratory. We versioned them like code, creating multiple variants because sentiment is subjective — what looks like noise to one researcher might be signal to another. Want dictionary exactly as published? Done. Want to see what happens when we boost emotional intensity based on arousal? That's there too. Each dictionary follows a simple naming rule: {NAME_VERSION} for the historical original, {NAME}_{VERSION}_{EXPERIMENT}for our experimental variations.
The API That Makes It All Work
from sentibank import archive
# Load a dictionary
load = archive.load()
vader = load.dict("VADER_v2014")
# Analyze some text
from sentibank.utils import analyze
analyzer = analyze()
# Score-based analysis
text = "I am excited and happy about the new announcement!"
result = analyzer.sentiment(text=text, dictionary="VADER_v2014")
# Returns: +4.1
# Label-based analysis
text = "Our shareholders will be pleased with these results"
result = analyzer.sentiment(text=text, dictionary="MASTER_v2022")
# Returns: {'Positive': 1, 'Negative': 0, 'Uncertainty': 0, ...}";
No more hunting through journal websites for that one CSV buried in “supplementary_material_v3_revised.zip”. No more parsing ancient file formats. Just pip install sentibank and you inherit an encyclopaedic hub of 15 sentiment dictionaries — 60 years of emotional archaeology in a single import statement. simple naming rule:
Why This Matters
As we transition from Software 1.0 (hand-coded rules) through Software 2.0 (trained neural nets), we're trading interpretability for capability. These sentiment dictionaries represent the last generation of machine we could fully understand — where every decision has a paper trail, every rule has an author, and every score has a justification.
Every sentiment score tells a story. A specific word, assigned a specific value, by a specific researcher, for a specific reason. When MASTER scores “liability” as negative, you can trace it back to Loughran and McDonald analysing 10-K filings in 2011. When VADER scores “lol” at +2.9, that's a weight with a backstory — not learned by backpropagation, but the collective wisdom of 10 vetted humans voting on how much happiness lives in three letters.
Download the Archaeology
We've open-sourced everything at our GitHub. The codebase is clean, the API is simple, and the dictionaries are ready to use.
But more importantly, we might need your help. Found a bug? Have a sentiment dictionary from 1987 gathering dust in your advisor's filing cabinet? Let's pool our resources. Check our contribution guidelines and help us expand this archaeological dig.
Because if we're preserving how Software 1.0 understood emotions, we're preserving more than code — we're preserving human judgement.
sentibank
Sixty years of emotion dictionaries. One import statement.
View all
Dataset
Product Review
OpinionLexicon
A dictionary for product reviews, comprising words curated for informal language

Dataset
Social Media
VADER
A gold-standard lexicon optimised for social media sentiment analysis

Dataset
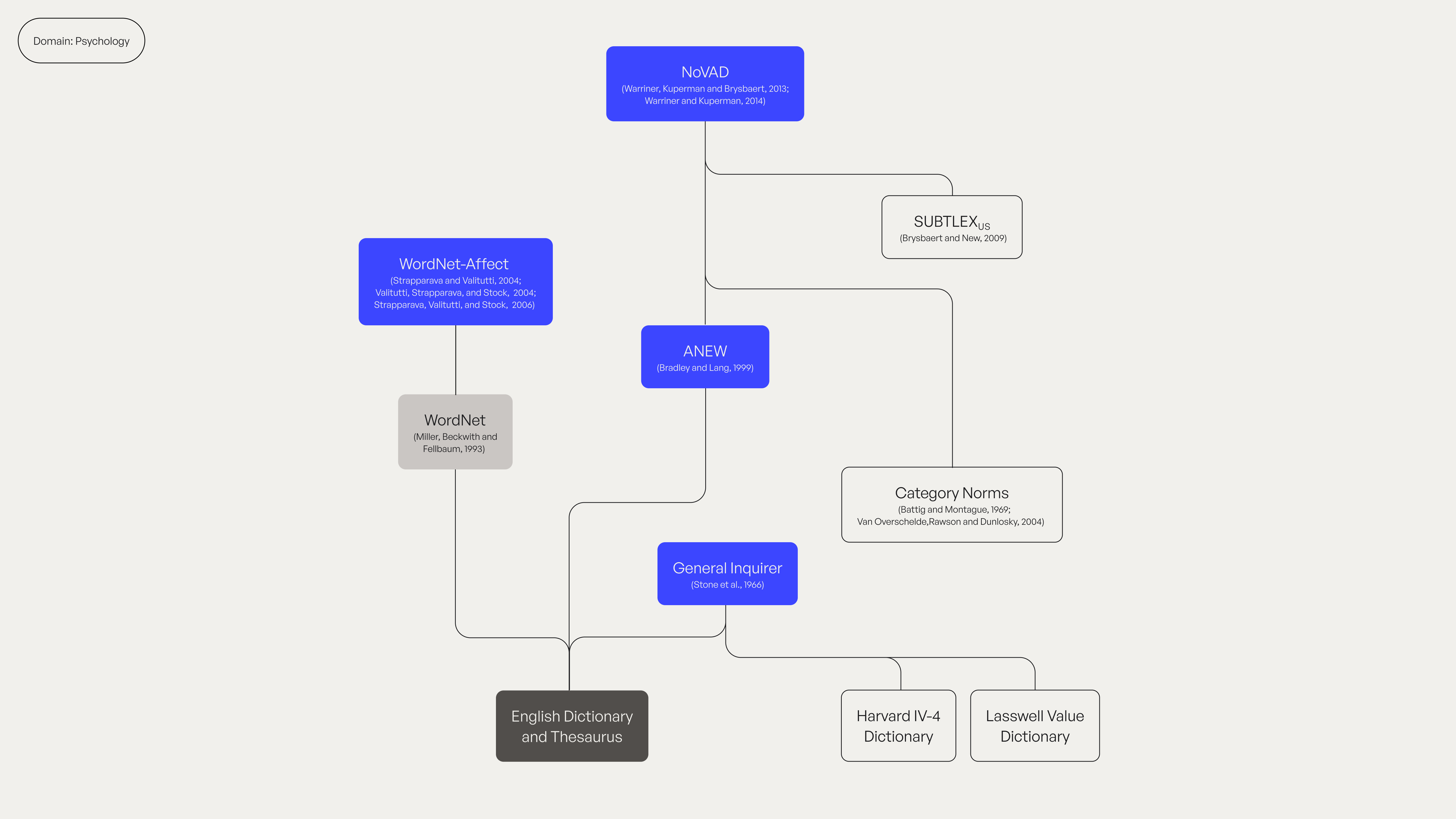
Psychology
WordNet-Affect
Affective labels that are hierarchically organised based on WordNet synsets

Dataset
General
SentiWordNet
A comprehensive dictionary that assigns graded sentiment scores to WordNet synsets


