Publication
AIES 2025
PETLP

Modern AI researchers don't just need GPUs and datasets — they need lawyers, or at least the ability to think like them. A single social media post triggers three separate legal interpretations. Copyright lawyers see intellectual property. Privacy regulators see personal data that must be anonymised. Platform lawyers see terms of service that prohibit your scraping. Each force is real, binding, and sometimes directly contradictory. After eighteen months charting these overlapping obligations, we built PETLP: a navigation system for researchers caught between scientific necessity and legal uncertainty.
The Access Wars
Remember when social media data was accessible for research? The golden age when downloading tweets didn't cost more than most people's rent.
By 2025, that era had thoroughly ended. CrowdTangle is dead (Meta cited shifting priorities). Pushshift is gone (Reddit claimed API violations). Twitter's Academic API now costs more than most research grants. Each platform has its reasons: limitations in providing a comprehensive view of platform activities, terms breaches, business models, sometimes privacy. Yet the same data remains available commercially through enterprise tiers and partnerships. When NYU researchers bypassed these restrictions using consented user data, Facebook didn't debate the ethics — they banned the accounts.
The regulatory environment offers no refuge. Only multiplication of uncertainty. Europe's privacy law (GDPR) says researchers get special exemptions, but won't tell you what counts as “research”. The copyright law says you can mine data for “research”, but stays silent on whether training AI is ok. When pressed, the European Data Protection Board admits that making social media truly anonymous is “difficult”. It's like being given driving directions where every other turn is “maybe left, possibly straight, definitely not right unless it's Thursday”, and the destination is just marked as “somewhere legal, probably”.
After watching these access battles destroy years of research, we stopped waiting for regulatory clarity and built our own navigation system.
Building PETLP: Structure for the Unstructured
PETLP stands for Privacy-by-design Extract, Transform, Load, and Present. It's the classic data pipeline with two modifications: privacy embedded from the start, and a fourth phase acknowledging that publishing research creates entirely new legal challenges.
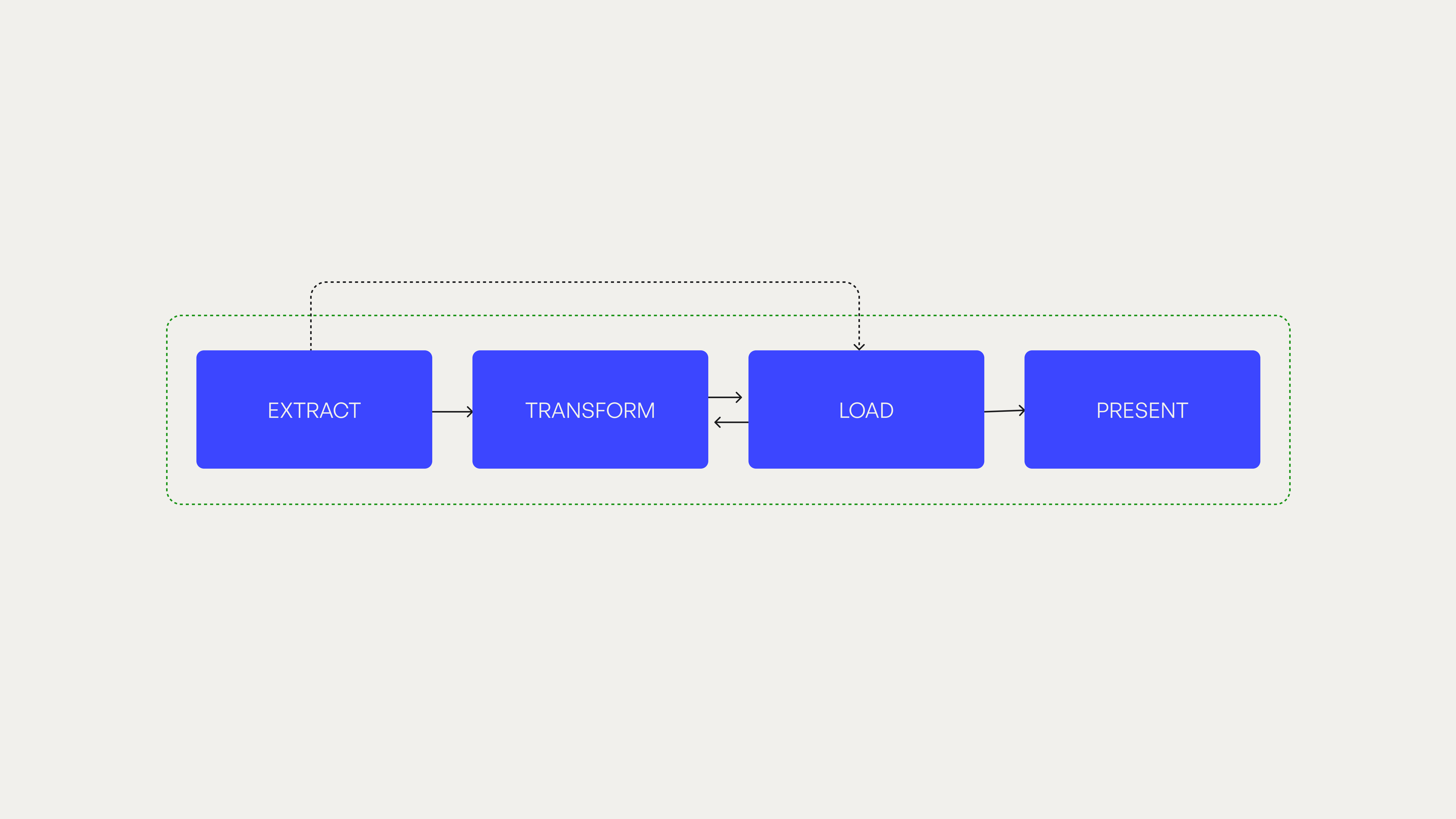
The framework starts with paperwork. Not the most exciting opening, we know. But what if privacy paperwork could make your research better, not just legal? A Data Protection Impact Assessment (DPIA) — think of it as a privacy risk audit that maps out what could go wrong before you start collecting data — becomes your research companion, not your compliance burden. Usually these end up in a drawer somewhere, signed but never consulted again. We treat them as living documents that evolve with your research, helping you spot privacy landmines before you step on them.
This isn't just about compliance (though yes, documented good faith beats scrambling for justifications). It's about forcing yourself to think through consequences before consequences force themselves on you. What data do you actually need? Who might be harmed? How will you protect them? In the sections that follow, we'll walk through the lessons we learnt — briefly, because nobody wants a 20,000-word blog post (that's what our paper is for). We're leaving out Load stage (from PETLP) because honestly, it's just ‘store your data securely and don't route it through dodgy servers’ stretched over several pages. Let's start with extraction, where we discovered four different doors to the same data, each with its own legal logic and moral calculus.
Four Doors, Four Realities
Think of Reddit's data like a building with four entrances: the front door (official API), the side door (user consent), the back door (third-party archives), and the window you open yourself (scraping). Each has different bouncers, different rules, and very different consequences if you're caught where you shouldn't be.
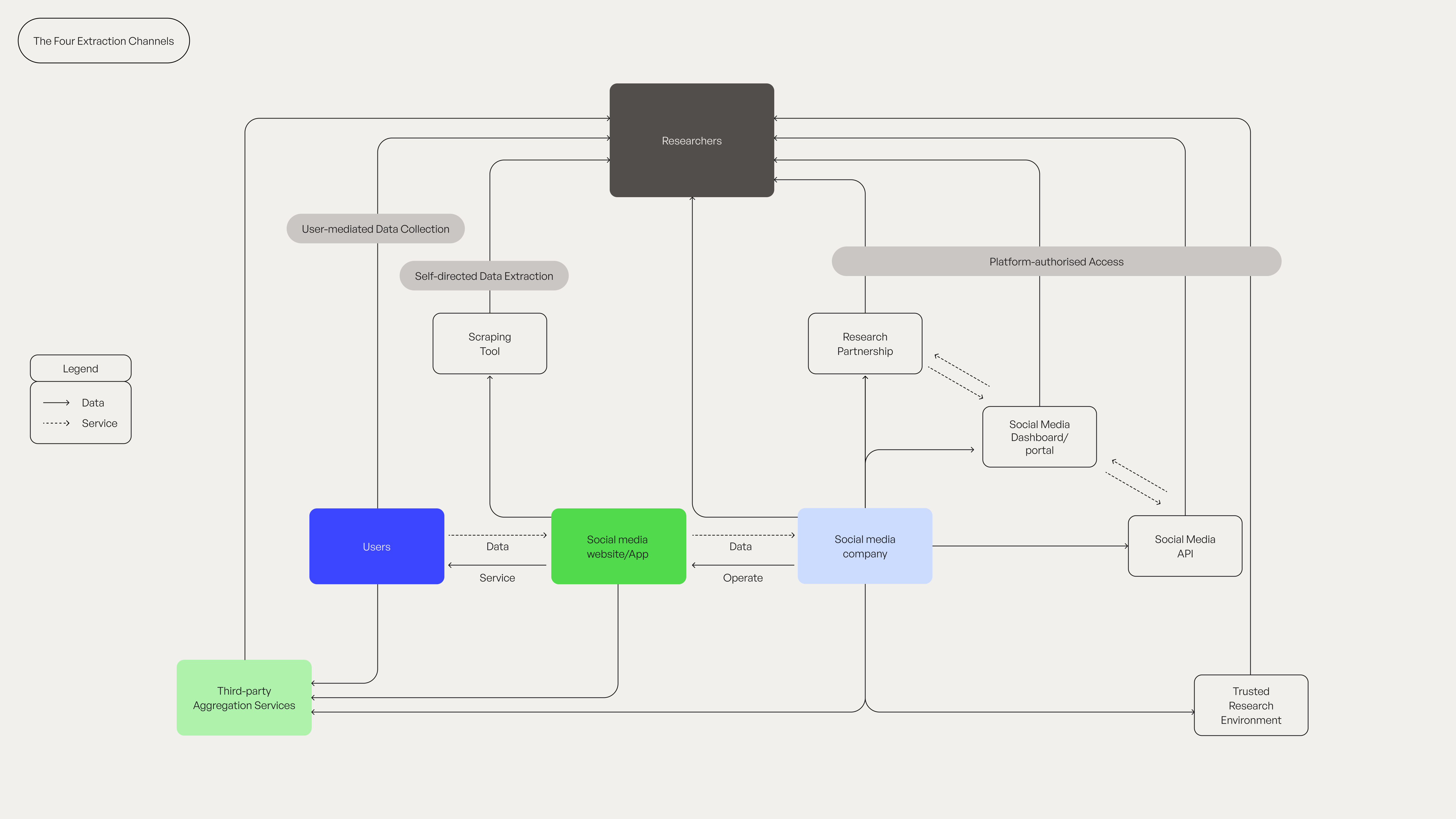
The Front Door (Official API): Platform APIs and partnerships. Clean, documented, expensive, limited. Reddit gives you 100 queries per minute but caps history at six months. Perfect for studying last week's discourse, less helpful for longitudinal research. The safest door is also the smallest.
The Side Door (User Consent): Users donate their own data. Ethically pristine, practically fraught. Even with explicit consent, platforms can claim contract violations. NYU learned this the hard way. Plus, your sample will skew toward the technically sophisticated. Not ideal for generalisable research.
The Back Door (Third-Party Archives): Third-party aggregators and archived datasets. Someone else took the legal risk; you inherit the legal uncertainty. Those 15TB of Reddit data on Academic Torrents? They come with a note saying content “may be protected”. That's not a licence; it's a legal liability of unknown magnitude.
The Window (DIY Scraping): Scrape it yourself. If you're a qualifying research organisation, DSM Article 3 protects you. The LAION v. Kneschke court confirmed platforms can't contract away statutory research rights. If you're a commercial entity, you're probably violating terms of service. If you're a startup doing “research”, welcome to the grey zone.
The Impossibility of Anonymisation
Transform isn't just about cleaning messy data — it's where you discover that “anonymising” social media is like trying to make water not wet.
Yes, true anonymisation of social media data proves difficult. This isn't pessimism; De Montjoye's research showed that 95% of individuals can be uniquely identified from just four spatiotemporal points. For social media, with its rich behavioural patterns and linguistic fingerprints, traditional de-identification techniques (stripping usernames, aggregating data, applying k-anonymity) amount to security theatre. They make re-identification slightly less convenient, not actually difficult.
This reality demands a different approach. Differential privacy offers the mathematically defensible path forward. Yes, it adds noise, and yes, it reduces utility. But the tools have matured — Opacus for PyTorch, TensorFlow Privacy for TF - and recent work demonstrates that 8B models can be fine-tuned with differential privacy (though the performance trade-offs are still being mapped out). The trade-off is real but manageable. You're not choosing between perfect privacy and perfect utility; you're choosing between imperfect privacy and no privacy at all.
What matters legally and ethically isn't achieving perfect anonymisation (impossible) but demonstrating serious engagement with privacy risks (possible). Document your differential privacy parameters. Justify your epsilon budget. Explain your noise addition strategy. Show that you understood the trade-offs and made deliberate choices to balance them. That paper trail — proving you engaged thoughtfully with privacy — becomes your defence when someone inevitably demonstrates that your “anonymised” dataset isn't.
The Publication Paradox
You've collected the data legally, transformed it carefully, stored it securely. But publishing your results might undo all that careful compliance. Because apparently, generating knowledge and sharing knowledge are two different crimes.
Legally collecting and processing data doesn't mean you can legally share your results.
The first problem is that models have memories. Your fine-tuned model — BERT, GPT, Claude, LLaMA, or whatever we're calling them by the time you read this — can recite training examples verbatim; that's the price of their intelligence. This means your model is carrying around fragments of personal data in its weights. Ask it the right question and it might repeat those personal details back. Under privacy law, that counts as 'processing personal data' — and you're responsible for it. The EDPB explicitly warns that models trained on personal data can't always be considered anonymous.
However, we still do not know whether training models on those datasets is also free from copyrights. There’s a case pending , and until such case provides clarity, publishing model weights exists in legal grey zone. Your model could be legitimate research output or massive copyright infringement. Nobody knows, and that uncertainty has a price tag attached.
Sometimes the Map Is All You Need
PETLP doesn't eliminate the structural tensions that make social media data simultaneously essential and restricted for AI research. Privacy and openness pull in opposite directions. Innovation bumps against compliance. Platform control tramples academic freedom. These aren't bugs in the system — they're features designed to protect different stakeholders with incompatible interests.
But understanding these constraints changes how you work within them. PETLP provides structure for navigating unstructured territory: decision trees that clarify your extraction options, living DPIAs that evolve with your research, risk frameworks that anticipate problems before lawyers arrive. The point isn't perfect safety. The point is proving you made deliberate choices rather than stumbling blindly forward.
We built this after our own research stalled mid-project, after watching Pushshift orphan hundreds of studies, after seeing too many researchers abandon social media work entirely. This framework is our refusal to let legal complexity kill AI research that depends on social media data.
We've mapped the maze not because we found the exit — there isn't one, at least not yet. We've mapped it because research must continue, even when the walls keep moving. Sometimes a good map through bad territory is exactly what you need.
PETLP is available at arXiv with decision trees, templates, and implementation guides. For Reddit researchers, we're rebuilding RedditHarbor from a simple crawler into guided PETLP compliance - automating not just data collection but the documentation and decisions that keep it defensible.
Built with cautious optimism at socius: Experimental Intelligence Lab


